Rich AICloud
AI原生云计算解决方案
彩讯AICloud是面向AI原生(AI-Native)的云计算解决方案。通过软硬一体化深度优化,为超大规模大模型训练、推理及算力租用提供高可用、高性能的AI算力集群支撑。
RichMoss
超大规模算力集群管理平台
云原生K8s优化万卡管理
RichNet
AI原生网络互联架构
RichBoost
高性能训推加速平台
●RichMoss 平台
RichMoss
超大规模算力集群管理平台
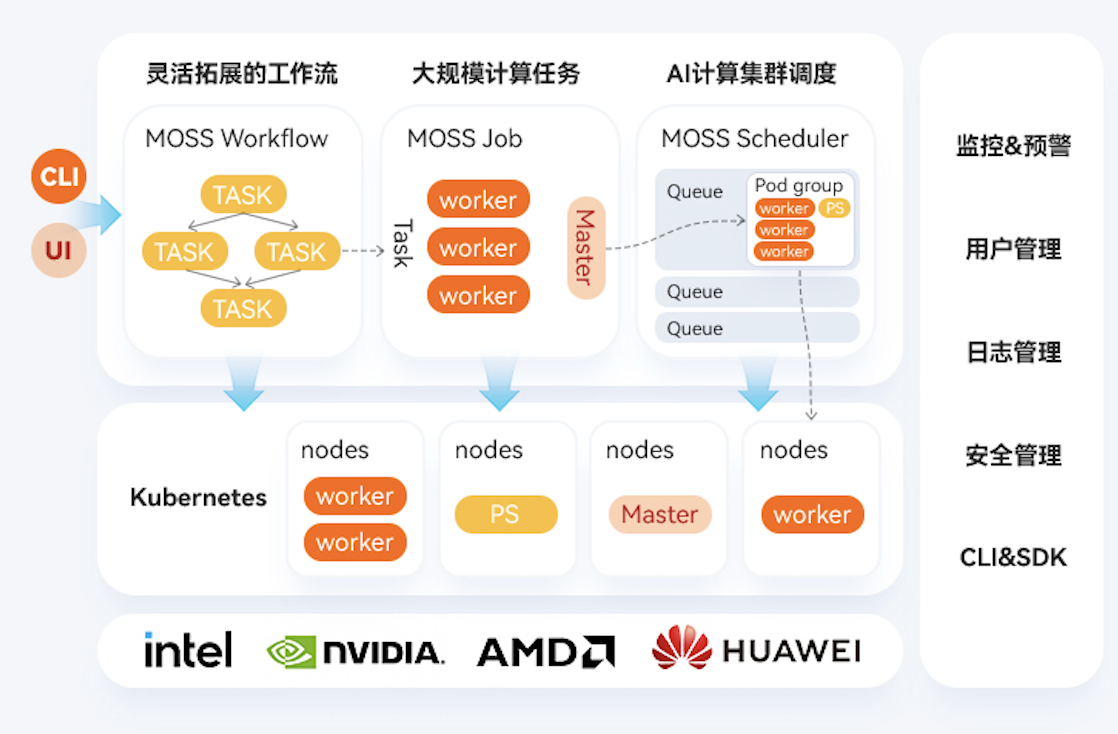
面向AI计算场景的超大规模算力集群管理平台,基于云原生Kubernetes架构深度优化,提供从资源调度、任务管理到运维监控的全栈集群治理能力,支持万卡级GPU集群的高效管理与稳定运行。

核心能力
打造稳定、高效、弹性的下一代AI算力底座
万卡级集群统一管理
- 超大规模支持:单集群可管理超10,000张GPU卡,已交付1万+卡生产环境
- 异构兼容:统一纳管NVIDIA、AMD、华为等多元算力设备
- 多租户隔离:支持多团队、多项目资源灵活隔离与共享,保障业务互不干扰
AI原生智能调度
- 高级队列机制:支持优先级、配额、抢占/恢复策略,保障关键任务资源供给
- 拓扑感知调度:基于GPU节点网络拓扑优化任务placement,减少通信开销
- 协同调度:支持任务组(Gang Scheduling)与资源协同分配,提升集群利用率
- 弹性伸缩:自动回收闲置资源,动态扩缩容,最大化硬件投资回报
灵活工作流编排
- 可视化DAG:支持复杂计算工作流的图形化编排,条件分支、失败重试、嵌套调用
- 多框架支持:原生适配TensorFlow、PyTorch、DeepSpeed、MPI、Ray等主流框架
- 模板复用:预置常用任务模板,一次编写多次调用,提升开发效率
自动化运维监控
- 端网一体化管控:整合服务器、网络、存储统一监控视图
- GPU状态实时监测:显存、温度、利用率、故障预警一目了然
- 智能故障诊断:自研训练监控模型,提前发现异常,故障率检测达70%
- 可视化运营:资源分配、使用模式、成本分析全局可视
平台指标效果
核心性能指标展示
集群管理规模10,000+GPU卡
故障恢复时间<1毫秒
人工运维减少50%
连续训练时长90天+
资源利用率提升55%
| 指标 | 数据 |
|---|---|
| 集群管理规模 | 10,000+GPU卡 |
| 故障恢复时间 | <1毫秒 |
| 人工运维减少 | 50% |
| 连续训练时长 | 90天+ |
| 资源利用率提升 | 55% |
产品架构图
RichMoss超大规模算力集群管理平台架构